【实话百科】什么是PPK

昨天说了什么是CPK,今天我们再来说说,很容易和它混淆的PPK。
简单的讲,PPK其实和CPK根本就是一回事,只是公式的计算方法稍微有点不同。
按照惯例,我们还是从5W1H的方法,来讨论这个问题。
- What,什么是CPK
- Why,为什么要用CPK
- When,什么情况下要用CPK
- Who,谁来做CPK
- Where,在哪里做CPK

什么是PPK
PPK是PerformanceIndex of Process的缩写,中文意思是制造过程性能指标。
网络上有很多关于CPK和PPK的解释,什么短期长期的,又是什么不考虑过程偏移,完全看不懂的学究解释。
要真正搞明白PPK和CPK的区别呢,还是得从公式入手。
1.1 PPK和CPK公式对比
首先我要向大家道个歉,在《【实话百科】,什么是CPK》里我讲的CPK公式,其实是PPK的公式。
先收好你的鸡蛋,和拖鞋!那个大兄弟,刀先放一旁,我跟你不熟。
事实证明,我也被混淆了。不过前面我说了,PPK和CPK其实就是一回事,从公式计算上来讲,确实如此,我们来对比一下两个公式。

从公式中可以看的出来,PPK和CPK的区别就在于,分母上的S和σ不一样,明白了这一点,会让我们对PPK和CPK有一个清晰的认识。
那么S是什么,σ又是指的什么呢?
1.2 S和σ有什么区别
S指的是用公式计算出来的标准偏差(又要道歉了,上一节课,我把它当成了σ),比如我们用Excel中的STDEV()函数,计算出来的就是S。
σ指的是什么呢?它是通过小组平均极差除以SPC常量得来的,叫做估计偏差。公式如下:

d2是一个查表查出来的数值,取决于我们抽样的方法。它和我实际量测的值没有关系。
看到这里,你可能已经开始蒙了。别急我先给你讲个故事。
1.3 关于标准差S和σ的故事
还是拿撕纸条这个例子来说吧。
话说,一开始的时候,我就拉着A同事和B同事,来做撕纸条这件事情,他们也是业余时间帮忙撕。数量也不多,一天撕个二三十个。质量也一般,参差不齐,因为没有专门的练习嘛。
后来,突然来了一个土豪老板,找到我们,知道我们有撕纸条的业务。下了一个10万pcs的订单,说他开了个棋牌室,急需1cm宽度的纸条,用来贴在对方牌友的脸上。好,我就专门成立了一个公司,专门撕纸条。
但是我们毕竟刚成立,人员都不专业,很多纸条撕的不符合1cm规格。老板就让我们发货之前,把每一个的纸条,都要量一遍,确认合格之后再发货。
后来经过一个多月的培训,A同事和B同事都练就了单手撕纸条的绝技,虽然不能分毫不差的等于1cm,但是误差基本不超过±0.1cm了。我们也不就用在发货之前,每一个纸条都量一遍了。
但是这种高强度的要求,一天两天可以,持续一两个星期,A同事和B同事就受不了了,他们也会累,也会偷懒,也就难免出现不合格的纸条。
突然有一天,棋牌室老板找到我说,有一批货出现了的大量不合格的纸条,让我们重新进行全检。这怎么能行呢?现在每天每个人要撕4000~5000pcs,根本量不过来,只能抽一部分来量。比如,每2小时,抽取5个进行测量。
故事讲完了,那么问题来了:要怎么评估,公司刚成立时,和人员熟练之后,1cm纸条生产过程的水平呢?
我来公布正确答案(以下仅代表拉登Dony的观点,欢迎高手指正)
- 公式刚成立时,使用PPK评估生产能力
- 人员熟练,生产稳定后,使用CPK评估生产能力。
PPK
PPK的分母是S,就是通过标准差公式STDEV()函数计算出来的结果。那么数值的分散程度,会直接影响S大小,也就影响了PPK的数值。
比如,A同事和老婆吵架了,带着情绪撕纸条,撕的乱七八糟。又比如,B同事得了帕金森,手不停的抖,撕的纸条也不合格。这些都会让数据变的很分散。
但是这些特殊原因,我们要考虑进去,因为是新公司嘛,人员不熟练,如果把这些因素都排除掉,虽然数据好看,但是会逼死自己。而STDEV()函数会把所有的数据,都计算进去。
CPK
CPK的分母是δ,它通过小组极差平均值,除以SPC常量得来的,公式如下:
其中d2是一个由表查出来的固定数字,那么重点就是R了。R是小组极差的平均值。只要小组内部的极差都很小,那么平均值就会很小,δ就会很小,CPK就会很大,这样计算出来的CPK会没有代表意义。
废话无用,我们用一组数据来佐证上面的观点。
假设现在我们从两个阶段里,分别统计了20个纸条的宽度,凑巧的是,两个阶段的数据完全相同,我们用PPK和CPK都计算一下,出来的结果如下:
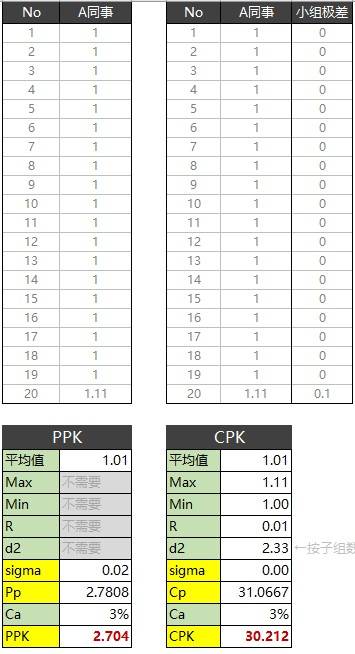
注意看,图中黄色部分单元格,是PPK和CPK不一样的地方。虽然两组数据完全相同,但是计算出来的结果,PPK和CPK差异非常大。
因为CPK中的sigma(也就是δ)是用R/d2算出来的,而R是小组极差的平均值。小组极差非常的小,所以δ非常的小。这样CPK就非常的大。
但是第20组数据,就是帕金森的B同事撕出来的啊。所以PPK比较正常的反映出了实际的情况。不是说CPK不如PPK好,而是这组数据,呈现出来的是,是不稳定的生产状态,不适合用CPK来统计。
等会,小组数据,是什么意思?
1.4 关于PPK和CPK的数据收集
上面我多次提到了小组数据,但是示例数据里没有看到小组啊?我又模拟了一份小组数据,一起来看看。

注意,不要和1.3中的数据进行对比,两个数据没有任何联系。上面的数据,有第1到第10组数据,每组有10个数据。假设我们是按照每2小时抽取10pcs产品,连续抽取10组,得到的共计100个数据(第10组是帕金森B同事入职了)。
这组数据,除了可以说明CPK和PPK的公式差别,还能体现数据的来源和统计规则不同。
PPK的计算
在计算过程中,PPK会把所有采集上来的100个数据,都作为一个整体来计算。相当于一次性收集100个数据,分析这个100个数据的过程能力。

CPK的计算
CPK则需要按照小组进行计算
- 首先计算每一组数据的平均值(得到表格中的第12行数据)
- 然后计算每一组的极差值(得到表格中的第13行数据)
- 然后对10个小组平均值,再求平均值。
- 对10个小组的极差值,求平均值。
- 根据小组极差的平均值,和查表得到的d2,计算出δ和CPK。

1.5 在Excel中计算S和δ
如前面所说,PPK里的S用Excel中的STDEV()函数,快速的计算出这个数值。
CPK里的δ,影响它的因素有两个,一个是小组间平均极差。
- 首先计算每个小组数据的极差值(就是最大值-最小值)。
- 所有小组的极差值求平均值,就是组间平均极差了。
另一个是参数d2,需要根据SPC常量表来查询。如下:

具体,可以关注【品管大实话】,回复PPK获取案例表格,以及SPC常量表,查看详细的公式。

为什么要用PPK
因为生产不稳定,特别是试产初期,很多特殊的原因,例如案例中说的帕金森B同事,如果小组内数据比较一致,这个时候CPK的结果,不能准确的体现小组之间的差异。
如果生产线已经趋于稳定,那就用CPK

什么情况下用PPK
如果你的生产线还不稳定,还处在试样初期,有帕金森这样的同事或者设备,那就使用PPK,因为CPK可能不准确。
如果生产线已经趋于稳定,那就用CPK。在生产稳定的状态下,一般PPK都会大于CPK,也就是说CPK会更加严格。

谁来做PPK
PPK和CPK是一个常用的计算方法,一个知识,谁都可以学,谁都可以用。

在哪里用PPK
应付客户的时候,报告里编数据的时候,都要用到PPK和CPK,明白了PPK和CPK的原理,数据编起来会更加省时,更加逼真。
对了,面试的时候,也有可能会被问到。回答完毕。
起立!下课!
本文完
源自拉登Dony的公众号【品管大实话】
转载请注明出处
联系作者