WebScraper的几个试用心得
1
什么是WebScraper
Web Scraper 是一个免费的谷歌浏览器扩展程序,它允许用户无需编写代码即可从网站中提取数据。用户通过简单的图形界面操作,就能创建抓取规则,实现对网页上各种信息的抓取,如文本、图片、链接等。
这两天我迷上了用WebScraper抓取网页信息,同事让我帮他写一个类似的插件。
自己做浏览器插件,我发现了一些局限性,特别是页面跳转时不太方便,于是转而使用了更专业的WebScraper插件。
2
其实之前我也尝试过,但总是搞不清楚Element click、Link、Pagination、这几个元素,所以这几天专门花时间研究了一下。
Element元素
简单来说,Element就是单页面里你要抓取的重复元素。几个要点,都要满足:
- 单个页面,网址不会发生变化
- 元素之间的样式是相同的,通常是class,或者原生标签比如div、ul、li等等。
Element Click元素
Element Click是指页面中需要【点击】之后才能查看信息的元素。关键要点:
- 页面的网址不会发生变化,否则会导致计算错误。
- 点击后,展示现的元素出来。
比如下面的导航栏中,点击1,才会显示2。
Link元素
Link也是点击元素,但区别在于点击后会跳转到新页面。关键要点:
- link元素中,要有链接地址,如果没有的话(比如用js代码跳转),会抓去失败。
- link有子元素,会点看链接抓去子元素内容。
- 如果没有子元素,就只返回链接地址。
比如点击标题,跳到一个新页面,如果要抓去文章的内容,就用Link。
Pagination
最后是Pagination,也就是导航按钮。点击后可以翻页,浏览不同的内容。关键要点:
- 连续的页码按钮
- Pagination会点击所有的页码(动态显示的也会点击),只到最后一页。

更多的深度的内容,下一节,再深入分享。
3
Link与Pagination元素的使用规则及区别
我仔细研究了一下Link这个元素,发现有几个关键点需要注意。
- Link元素里面必须包含超链接,否则无法选择。
- Link点击之后的网址也要有变化,如果网址不变,那就不能使用Link元素。
- 如果要点击的元素,是通过JavaScript来更改浏览器链接的,那么必须选择最后一项【Link from any script 】来打开链接。
Pagination使用注意事项
Pagination也是点击元素,跳转到不同页面抓去数据,和Links的区别在于:
可以用在JS按钮上
Pagination可以识别出链接和JavaScript的导航条,所以如果是针对导航的话,推荐使用Pagination。
会点开所有的页面
Pagination会针对选择的元素挨个点击,直到把整个页面所有的页面都抓取完成,所以这个时间可能会比较长。
比如有的导航条里面只显示了10个,但实际上可能有2500页,它就要把2500页都抓完。
而Links只会点击看到的这10个按钮。
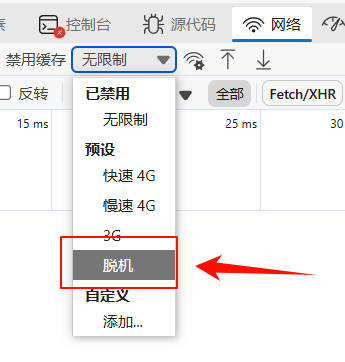
如何停止Pagination抓取?
可以使用浏览器的网络模拟脱机状态,让Pagination停止
Element click和link的区别
比如,我要点击链接,抓取每个帖子的内容。用Link还是Eelement click?
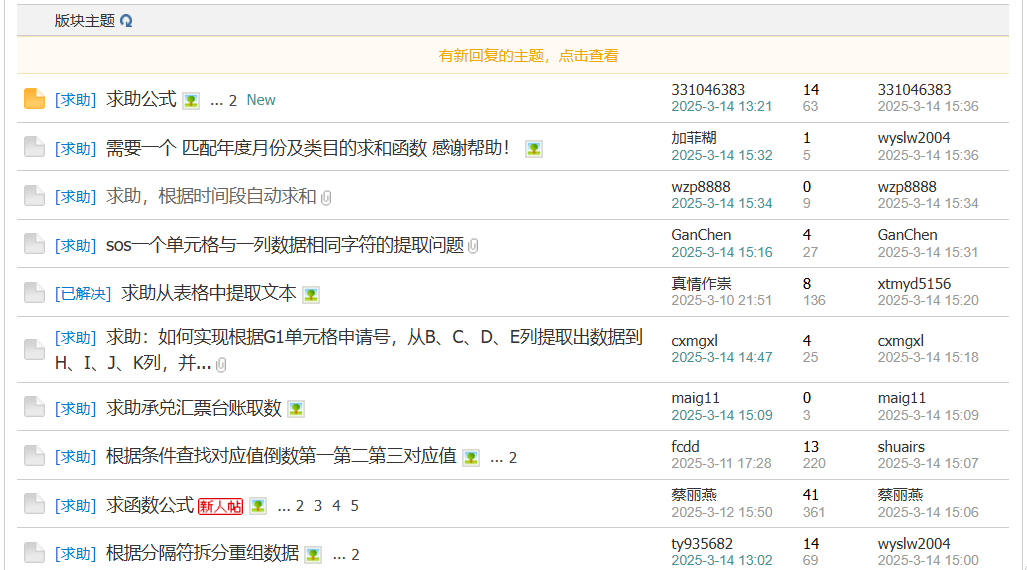
基本的原则是:
- 链接改变,用Link
- 链接不变,有Element click
还有一种情况,点击【更多按钮】,页面链接没有变化,但是内容增加了。
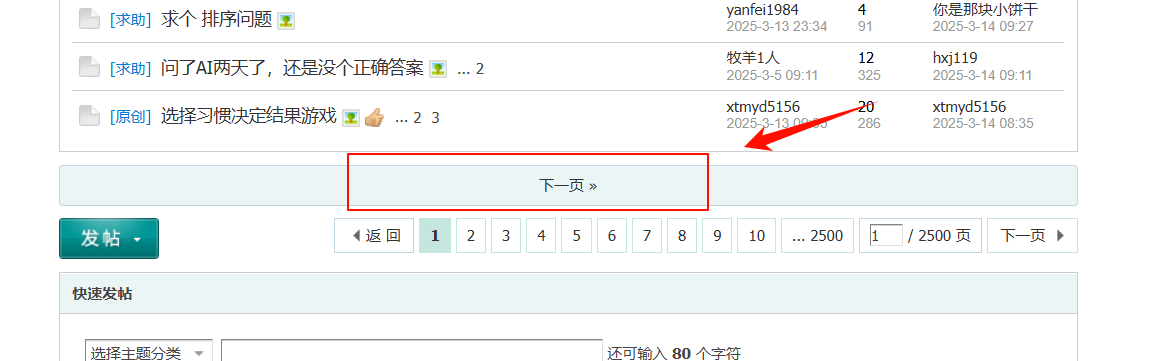
这种情况,有两种方法:
- 用Pagination翻页(推荐),添加子元素用element抓取数据。
- Element click翻页,添加子元素用element抓取数据。
用哪个网站来学习比较好?
刚测试了一下,用Excel home网站学习挺不错,里面有各种导航。不过,若使用pagination功能。
使用Pagination的时候注意,若网址发生变化,数据能实时更新,在WebScraper里点击刷新数据即可;
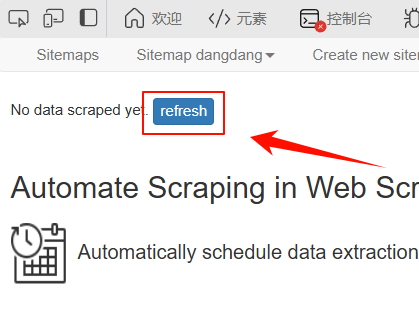
但如果网址未更新,点击刷新数据则无法得到结果。
联系作者